Back to 2025 Abstracts
Evaluating the Appropriateness of Large Language Model Recommendations for Overactive Bladder Management
Architha Sudhakar, MD1, Divya Ajay, MD, MPH
2, Sanchita Bose, MD
1.
1Maine Medical Center, Portland, ME, USA,
2Memorial Sloan Kettering Cancer Center, New York City, NY, USA.
BACKGROUND:Overactive bladder (OAB) is an increasingly common condition in the United States, however many regions have limited access to urologic care. Large language models (LLM) such as ChatGPT have demonstrated the ability to enhance clinical workflow, including providing recommendations for screening guidelines and answering questions regarding clinical management. This offers potential to reduce primary care provider burden in under-resourced settings, particularly where access to specialized urologic care is scarce. We evaluated the ability of these LLM’s to generate appropriate recommendations on basic clinical scenarios for OAB management.
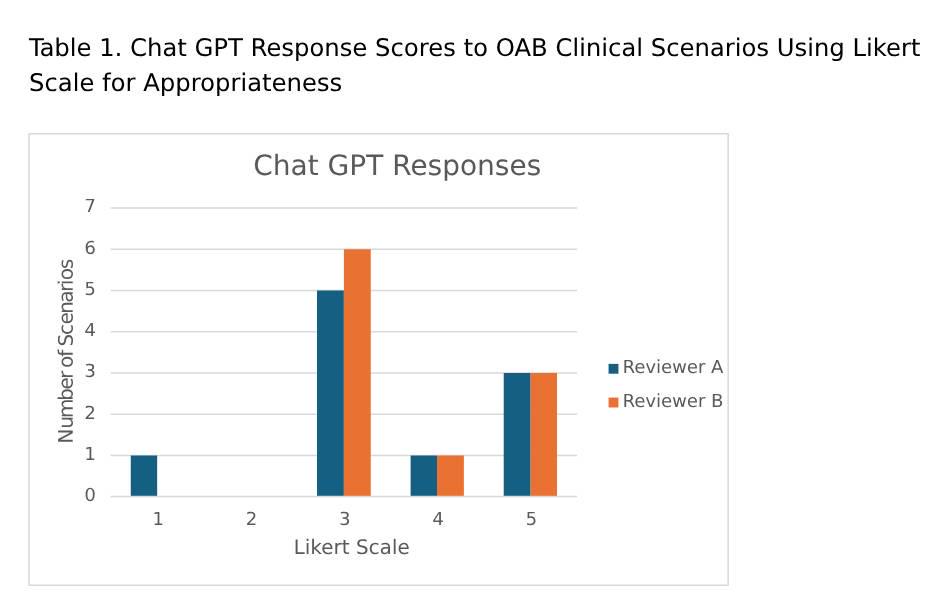
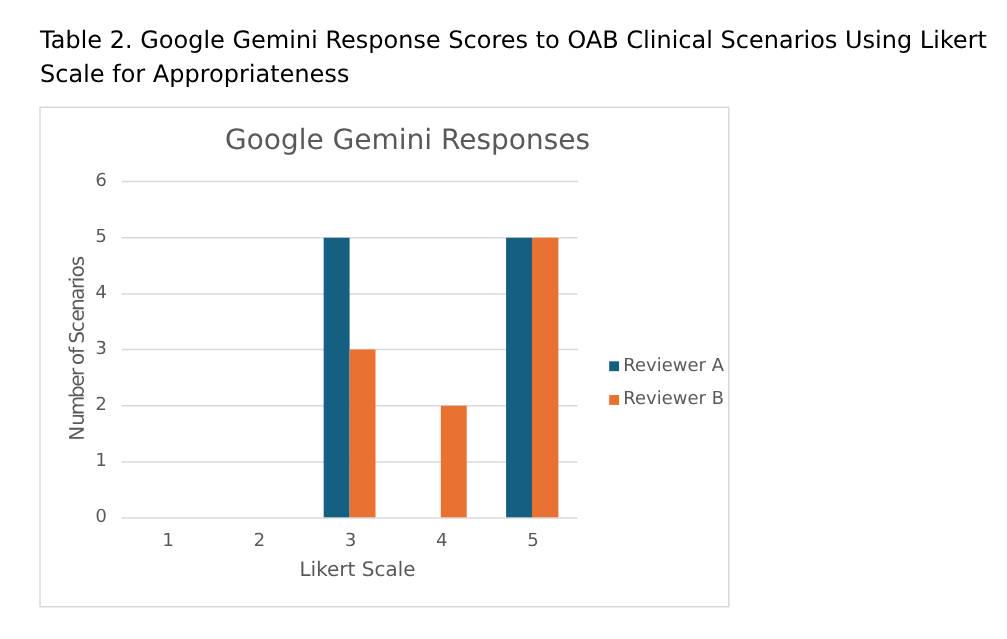
METHODS:A set of ten clinical scenarios encompassing OAB evaluation and management were used to query two LLM models- Chat GPT 4.0 and Google Gemini 2.0. Their responses were blinded and distributed to two independent fellowship-trained urogynecology and pelvic reconstructive surgery (URPS) urologists. A five-point Likert scale for appropriateness was used to assess concordance of LLM recommendations with current AUA/SUFU guidelines.
RESULTS:There was no significant difference in response appropriateness between Chat GPT and Google Gemini (p=0.158). However, Google Gemini did achieve a higher median appropriateness score of 4.5 compared to Chat GPT with 3.0 (Figure 1-2). The Cohen Kappa interrater score was 0.26, indicating fair agreement between the reviewers.
CONCLUSIONS:Despite LLM’s ability to offer generally accurate clinical recommendations, responses often lacked critical information or differed with expert advice. Both models also produced similar responses for all scenarios and failed to incorporate individual patient data. While promising, further research is needed to understand LLM’s strength and limitations prior to implementation in a clinical setting.
Back to 2025 Abstracts


